Deploy production-grade AI directly on your hardware — fully offline, private, and cost-free to run.
I embed advanced AI into phones, IoT devices, Raspberry Pi clusters, and NVIDIA Jetson systems using Google Gemma 4 edge models — enabling real-time, multimodal intelligence without cloud dependency.
- No API costs
- No data leaving the device
- No latency from cloud calls
Just fast, private, on-device AI.
What This Means for Your Product
- AI runs entirely offline
- Supports text, image, audio, and video
- Works in low-bandwidth or air-gapped environments
- Suitable for privacy-sensitive industries (GDPR / HIPAA)
- Enables AI-native hardware products
Why Gemma 4 Edge Models
E2B
- Efficient runtime (~2B effective parameters)
- Fits within <1.5 GB RAM
- Ideal for embedded and constrained devices
E4B
- Higher reasoning capability
- Better for complex multimodal tasks
Shared Capabilities
- 128K context window
- Up to 30s audio + 60s video processing
- Apache 2.0 license (no licensing cost)
- Single unified multimodal model
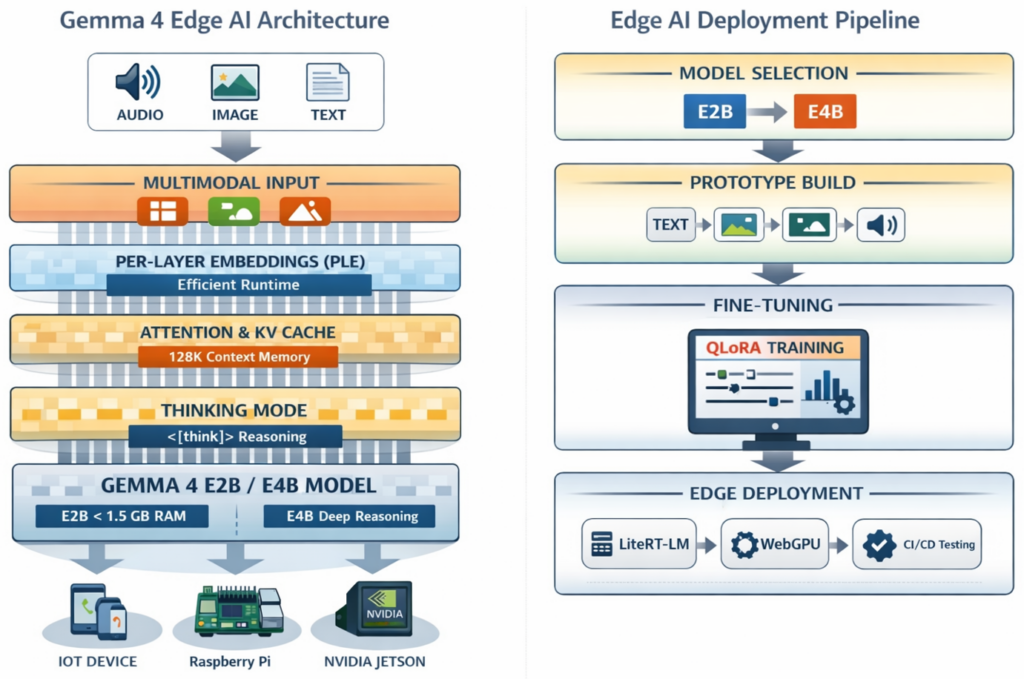
Technical Depth — What I Actually Do
Architecture (PLE Efficiency)
Gemma 4 uses Per-Layer Embeddings (PLE) — runtime compute behaves like a smaller model while retaining larger weight capacity.
I design systems based on effective compute cost, not just parameter size.
Correct Model Handling
Multimodal inference requires:
AutoModelForMultimodalLM(not image-text classes)- Correct processor pipelines per modality
- Audio resampling at 16 kHz
Getting this wrong leads to silent failures — I handle it correctly from the start.
Attention & Memory Optimisation
- Hybrid sliding window + global attention
- Unified KV cache strategy
Critical for:
- Running 128K context on constrained edge devices
- Managing memory vs latency trade-offs
Thinking Mode (Advanced Prompting)
<|think|>token enables reasoning mode- Thought traces must be stripped before reuse
Improper handling reduces multi-turn performance — I design pipelines that avoid this.
Fine-Tuning (QLoRA)
- 4-bit NF4 base + bfloat16 adapters
- Target modules:
q_proj,v_proj - Rank tuning (16–64 depending on task)
Supports multimodal training pipelines using TRL.
Deployment Optimisation
- LiteRT-LM (Android, <1.5GB RAM)
- WebGPU (browser deployment)
- Quantisation:
q4_K_M→ speedq8_0→ accuracybf16→ benchmarking
Engagement Options
1. Strategy & Architecture (1–2 Weeks)
- Use-case validation
- E2B vs E4B selection
- Hardware scoping (Pi, Jetson, Edge SoCs)
- Memory + KV cache planning
2. Prototype / PoC (2–4 Weeks)
- Working multimodal system on your device
- Correct pipelines (text, image, audio)
- Performance benchmarking
3. Deployment & Optimisation (2–4 Weeks)
- QLoRA fine-tuning
- Quantisation & optimisation
- LiteRT-LM / WebGPU deployment
- CI pipeline + production handover
Industries & Use Cases
Healthcare
- Voice-to-report systems
- On-device patient summarisation
- Fully private (no data leaves device)
Manufacturing
- Visual defect detection (Jetson)
- Offline quality inspection systems
Retail & Logistics
- Receipt OCR (offline)
- Voice-based inventory lookup
- Works in warehouses without connectivity
Consumer Devices
- Always-on voice assistants
- Smart cameras with local AI
- Embedded AI products
Supported Hardware
- Raspberry Pi (standalone & clusters)
- NVIDIA Jetson (Nano, Xavier, Orin)
- ARM-based embedded systems
- Edge AI SoCs
- Browser (WebGPU deployment)
Why Work With Me
I don’t apply generic LLM knowledge to edge systems.
I understand how Gemma 4 actually works at runtime:
- PLE architecture
- Hybrid attention
- KV cache constraints
- Multimodal model class differences
And I translate that into real hardware performance.
What You Get
- Production-ready, documented code
- Reproducible benchmarks
- Clear architecture decisions
- Weekly progress demos
- Fully remote, async delivery
Technical Stack
Core
- transformers ≥ 5.5.0
- accelerate · librosa
Fine-tuning
- TRL · PEFT / LoRA
Deployment
- Android (LiteRT-LM)
- Raspberry Pi · Jetson
- Browser (WebGPU)
Quantisation
- q4_K_M · q8_0 · bf16
- NF4 (QLoRA base)
- GGUF (llama.cpp)
Book a free 20-minute scoping call
Book a free 20-minute scoping call
→ Get exact model + hardware recommendation
→ Clear deployment path
→ No guesswork

